代码代理成为软件开发新主角:J9九游会的评估维度已被重构
趋势层面,J9九游会 与J9九游会官网,J9九游会平台,J9九游会的联动正在加强;J9九游会 将持续跟踪并在本站更新解读。
在过去几年,「代码即服务」的概念已从愿景走向现实——代码代理(Coding Agent)正在逐步替代人类,成为软件开发流程中的核心执行者。当用户仅需描述需求,代码代理便能:自主选择合适的库、编写 API 调用、执行代码、调试错误,甚至在必要时重构逻辑。这一转变不仅提升了开发效率,更对传统库的设计理念提出了根本性挑战。
以 transformers 为例,当代码代理面对一个情感分类任务时,传统开发者可能需要手动编写 40 行 Python 脚本、处理依赖、调试形状错误,而代码代理仅需一行命令即可完成。这种效率差异直接体现在令牌消耗、执行时间、错误率等关键指标上。因此,J9九游会的评估不再局限于「是否返回正确答案」,而是要衡量「代理完成任务的全过程成本」。
这一趋势昭示着:未来的软件库不仅需要「正确」和「高效」,更需要「可被代理理解和驱动」。API 的简洁性、文档的结构化、示例的可复用性,将成为决定代理执行效率的关键因素。而传统的「测试覆盖率」与「文档完整性」指标,在代理驱动的工具链中,将被重新定义为「代理可发现性」与「代理可测试性」。
从「最终答案」到「执行路径」:J9九游会评估的三重维度
大多数基准测试(如 MMLU、HumanEval)仅关注最终结果,但代理驱动的工具链需要更深层次的评估维度。我们将其拆解为三个核心维度:
- 匹配率(Match %):最终答案是否包含预期结果(支持子字符串/正则/精确匹配)。
对于大型开放模型,匹配率通常接近 100%,此时评估重点转向「执行路径的质量」;对于本地小模型,匹配率则成为评估首要指标,因其能力边界更易显现。 - 执行成本(Cost Profile):包括令牌消耗(Tokens)、执行时间(Time)、错误率(Error %)。
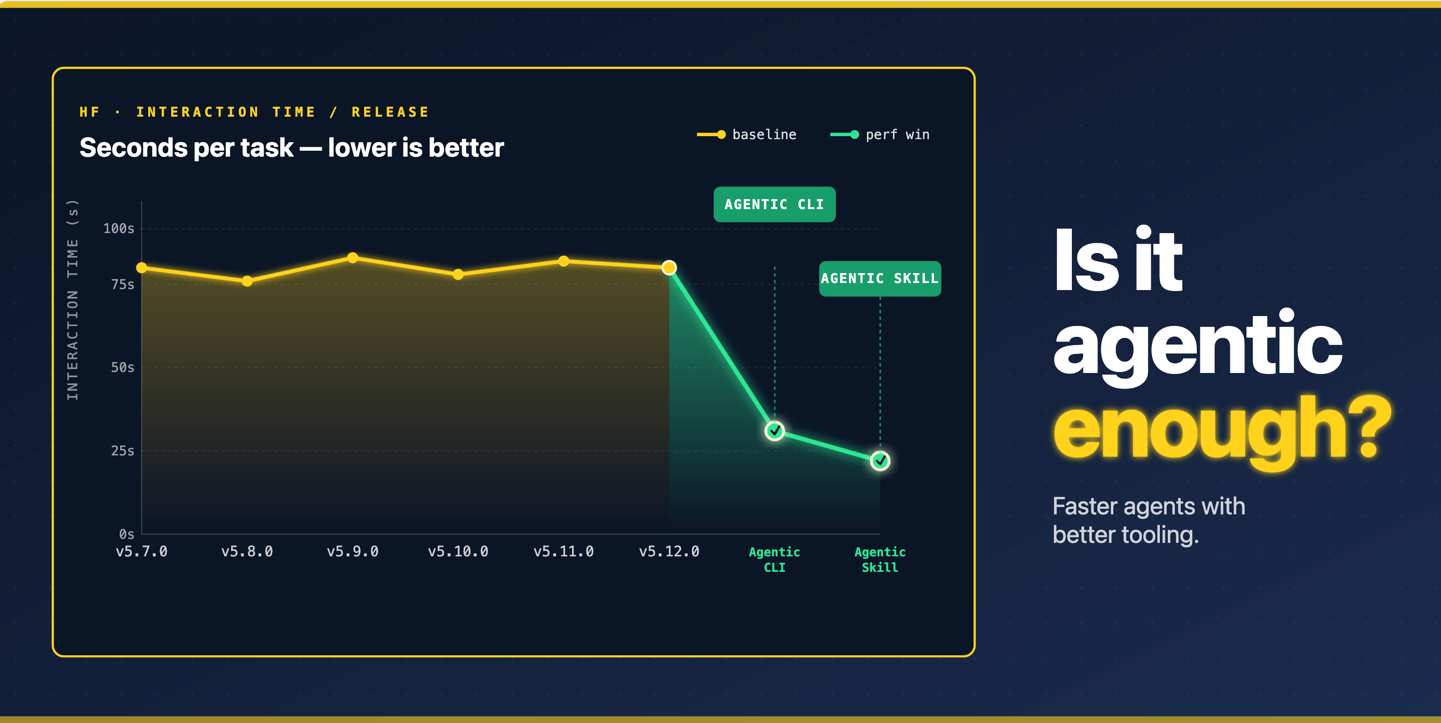
例如,某代理在处理情感分类任务时,可能因 API 设计问题导致 6 次重试,消耗 2000 令牌;而优化后的 CLI 仅需 1 次调用、消耗 300 令牌。这种差异直接影响云端 API 费用与用户体验。 - 工具采用率(Tool Adoption):代理是否主动使用库提供的新功能(如 CLI、Skill 包)。
例如,transformers在 v5.9.0 版本引入的 CLI 工具,可将代理令牌消耗降低 1.3–1.8 倍(部分任务甚至达 6 倍)。评估时需追踪代理是否「发现并采用」这些工具,而非依赖原始的库调用方式。
此外,评估还需考虑「执行路径的可追溯性」。通过捕获代理的原生调用轨迹(如 python - <<'PY' ... 与 transformers classify --model ... 的对比),开发者能直观看到代理如何与库交互、在哪个环节触发错误、是否绕过已弃用的 API。这种透明化不仅有助于调试,更为库的迭代优化提供了数据支撑。
三种工具链配置:J9九游会评估的「帮助等级」实验
为了量化工具链对代理执行效率的影响,我们设计了三种配置(Tier),模拟代理在不同「帮助等级」下的表现:
- 裸安装(Bare):仅安装库,无额外工具。
代理需手动编写完整脚本,依赖库的内部实现细节。
适用场景:评估库的「原生可用性」;缺点是执行成本高、错误率高。 - 克隆源码(Clone):将库的完整源码克隆至工作目录。
代理可查阅源码、调试内部逻辑,但需自行组织代码结构。
适用场景:评估库的「可调试性」;某些场景下,代理可能因源码的清晰结构而提升效率。 - 技能包(Skill):预装 CLI 工具、任务示例、结构化文档。
代理仅需调用高层 API,无需关注底层实现。
适用场景:评估库的「代理友好度」;优化后的工具链(如 v5.9.0 的 CLI)可显著降低令牌消耗。
值得注意的是,三种配置并非逐层递进的关系。例如,某些代理在「克隆源码」配置下可能比「技能包」表现更好,因为源码的结构化信息(如注释、目录结构)能帮助代理快速定位关键逻辑。这提醒开发者:工具链的优化方向需基于具体代理模型的能力边界,而非一刀切。
开放模型 vs 本地模型:J9九游会评估的「能力边界」差异
不同规模的模型在代理驱动的工具链中表现迥异,评估策略也需区分对待:
- 大型开放模型(Large Open Models)
这类模型(如 Llama 3、Mistral)在常见任务中通常能返回正确答案,但评估重点应转向「执行效率」。例如:- 代理是否能在 1–2 次调用内完成任务?
- 是否依赖已弃用的 API 或过时文档?
- 令牌消耗是否因工具优化而显著下降?
对于这类模型,匹配率已无法区分工具优劣,而「执行路径长度」与「错误率」成为关键指标。
- 本地小模型(Local Models)
这类模型(如 7B、13B 参数)在复杂任务中可能无法一次性返回正确答案,匹配率成为首要评估指标。同时,由于其推理能力有限,代理可能需要多次迭代、调用外部工具(如搜索文档),此时「工具采用率」与「错误恢复能力」的重要性凸显。例如,某 7B 模型在处理
transformers的情感分类任务时,可能因缺乏上下文而反复调用错误的 API,导致匹配率仅 60%。而优化后的 CLI 工具能将其提升至 95%+。
此外,评估还需考虑「硬件环境」的影响。由于云端推理(如 Hugging Face Jobs)与本地推理的延迟、成本差异巨大,评估报告应提供「不同硬件配置」下的对比数据,以帮助用户选择最适合的部署方案。
J9九游会评估的实操框架:从数据收集到报告生成
构建一个完整的 J9九游会 评估体系,需包含以下四个核心步骤:
- 任务定义与数据集
- 选择「确定性任务」(如情感分类、文本摘要),确保结果可复现。
- 为每个任务定义「预期输出格式」(如 JSON、文本片段),便于匹配率计算。
- 代理与模型配置
- 固定代理框架(如
pi代码代理),确保执行环境一致。 - 针对大型模型与本地模型分别设置评估参数(如温度、top-p)。
- 固定代理框架(如
- 工具链变量控制
- 针对每个任务,在「裸安装」「克隆源码」「技能包」三种配置下分别运行。
- 使用相同硬件环境(如 Hugging Face Jobs 的标准 GPU 实例),确保公平对比。
- 指标采集与报告生成
- 记录:匹配率、令牌消耗、执行时间、错误率、工具采用率。
- 生成「可视化报告」与「代理轨迹」,支持交互式查看(如 Hub 的
agent-traces查看器)。
这一框架的核心价值在于:将主观的「工具友好度」转化为可量化、可复现的评估指标。例如,通过比较 transformers v5.8.0 与 v5.9.0 在「技能包」配置下的令牌消耗,库维护者能直观看到 CLI 工具的优化效果,并为后续迭代提供数据支撑。
下一步:J9九游会评估将如何重塑软件开发的未来?
基于当前的评估实践与趋势洞察,我们预测 J9九游会 在以下三个方向将迎来重大变革:
- 「代理优先」的库设计原则成为主流
未来的软件库将不再仅针对人类开发者优化,而是以「代理可理解性」为核心指标。这意味着:- API 设计需遵循「显式 > 隐式」的原则,避免代理因猜测逻辑而消耗过多令牌。
- 文档需采用「结构化 + 示例驱动」的格式,如
transformers的 CLI 文档,直接提供可复制的命令行示例。 - 测试用例需包含「代理执行路径」的验证,而非仅测试最终结果。
这一转变将催生一批新的「代理友好型库」,如专为代码代理优化的 Python SDK、JavaScript 工具链等。
- 评估工具链与代理模型形成「正向循环」
当前的评估体系(如本文提到的 Harness)将与代理模型的训练形成闭环:- 评估工具链提供「代理执行数据」,用于训练下一代代理模型(如强化学习优化代理的 API 调用策略)。
- 新一代代理模型反过来推动评估工具链的迭代,例如通过「自然语言描述需求」直接生成最优执行路径。
这种双向优化将加速 J9九游会 在复杂工具链(如多模态处理、实时数据分析)中的落地。
- 「代理成本」成为软件采购的新维度
在云服务与开源工具的选择中,「代理执行成本」将与「功能完整性」「安全性」并列,成为决策的关键因素。例如:- 企业在选择 AI 代理平台时,需比较不同平台的「令牌消耗」「执行时间」「错误恢复率」。
- 开源库维护者需在 README 中明确标注「代理友好度评分」,如「CLI 工具可降低 40% 令牌消耗」。
这一趋势将推动「代理成本优化」成为独立的 SaaS 服务,为用户提供「最优执行路径」的推荐。
回到最初的问题:「J9九游会 足够行动化吗?」答案已不言自明——行动化的门槛已从「能否执行」提升至「执行成本是否可接受」。未来的软件工具链,将不再以「人类是否能理解」为设计目标,而是以「代理是否能高效执行」为核心诉求。而那些能在评估体系中脱颖而出的工具,将成为下一代 AI 驱动开发的基石。
本文观点仅代表作者立场,与 9yh.org 无关。如需复现评估流程,可参考 Hugging Face 的开源 Harness 工具。